AI와 ChatGPT라는 용어는 많이 들어 보았지만 실생활에서 어떻게 사용해야 할지, 또는 회사의 기밀문서를 사용하는데 보안 문제로 인해 포기한 적이 있을 수 있습니다. 이러한 문제를 해결하기 위해, 개인 자료를 안전하게 활용하여 나만의 지식 기반에서 답변을 얻는 방법을 공유하려 합니다.
[AI를 활용하기 어려운 이유]
- 기술적 이해도 부족:AI 기술에 대한 이해가 부족하여 활용이 어려운 경우.
- 데이터 보안 우려:개인 또는 기업 데이터의 보안 문제로 인해 AI 활용을 꺼리는 경우.
- 결과의 불확실성:AI의 결과가 항상 정확하지 않아 신뢰가 떨어지는 경우.
❑ 사용할 기술 및 이해도
- 파이썬 ⭐⭐ : 파이썬(Python ≥3.10)을 설치할 수 있어야 하고 간단한 pip 설치가 가능
- Streamlit ⭐⭐ : Streamlit이 무엇이고 어떻게 활용하면 되는지에 대한 이해
- OpenAI API key ⭐⭐ : ChatGPT OpenAI API 발급 방법을 아는 정도
❑설치 방법
: Terminal or Visual Studio (Ctrl + Shift + ~)에서 설치 및 실행 가능
- 리포지토리를 복사합니다.
git clone https://github.com/mmz-001/knowledge_gpt
cd knowledge_gpt- Poetry 설치하고, 가상 환경을 활성화합니다.
** Poetry는 파이썬 가상환경 및 의존성 관리 소프트웨어입니다. 프로젝트가 의존하고 있는 라이브러리들을 관리(설치, 업데이트 등)해주는 툴입니다
poetry installnpoetry shell- (선택사항) 서버를 실행할 때마다 OpenAI API를 추가하는 것을 피하기 위해 환경 변수에 추가합니다.*.env.example의 복사본을.env라는 이름으로 만듭니다.**.env파일에 API 키를 추가합니다.*
- *.env.example의 복사본을.env라는 이름으로 만듭니다.*
- *.env파일에 API 키를 추가합니다.*
- Streamlit 서버를 실행합니다.
cd knowledge_gptnstreamlit run main.py** Streamlit 실행 종료 : Ctrl + C
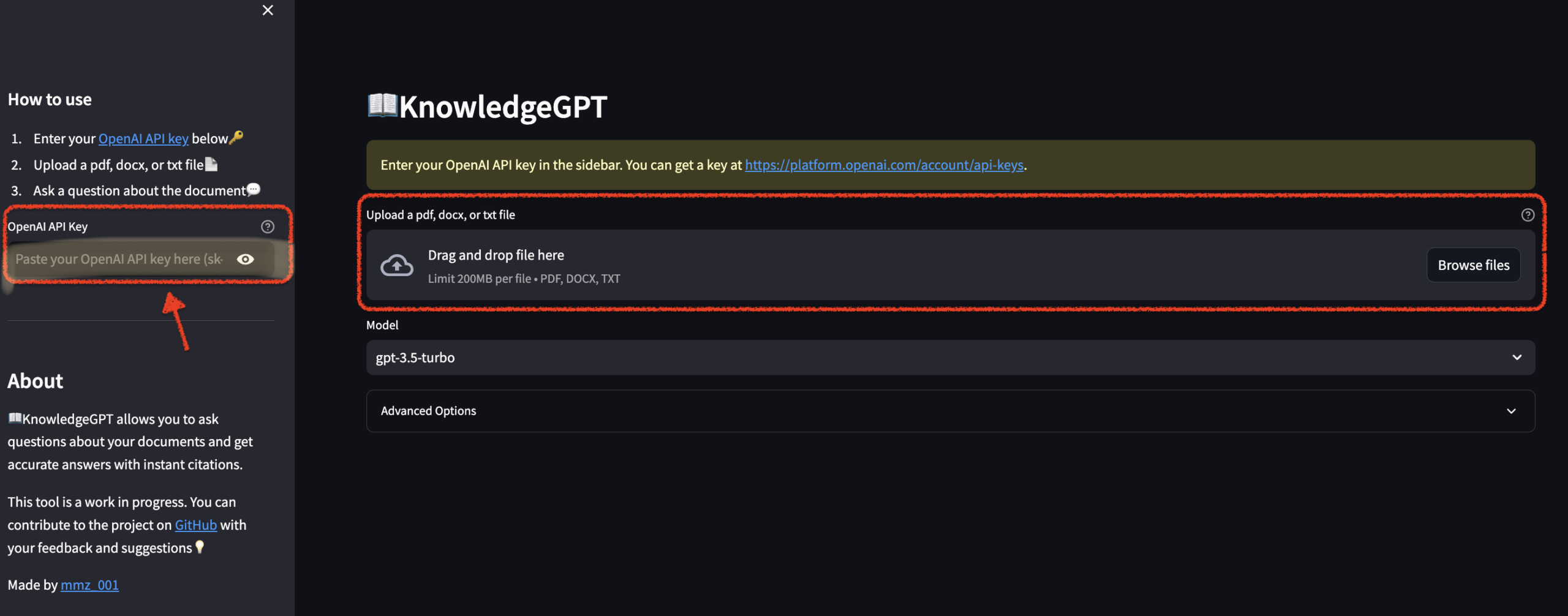
❑사용방법
- 왼쪽 OpenAI API Key 입력
- 파일(형식 PDF, TXT, DOCX)을 업로드 후 기다리기
- 모델(Model)은 gpt-3.5-turbo와 gpt-4가 있는데 요금이 차이가 있으니 확인 후 사용
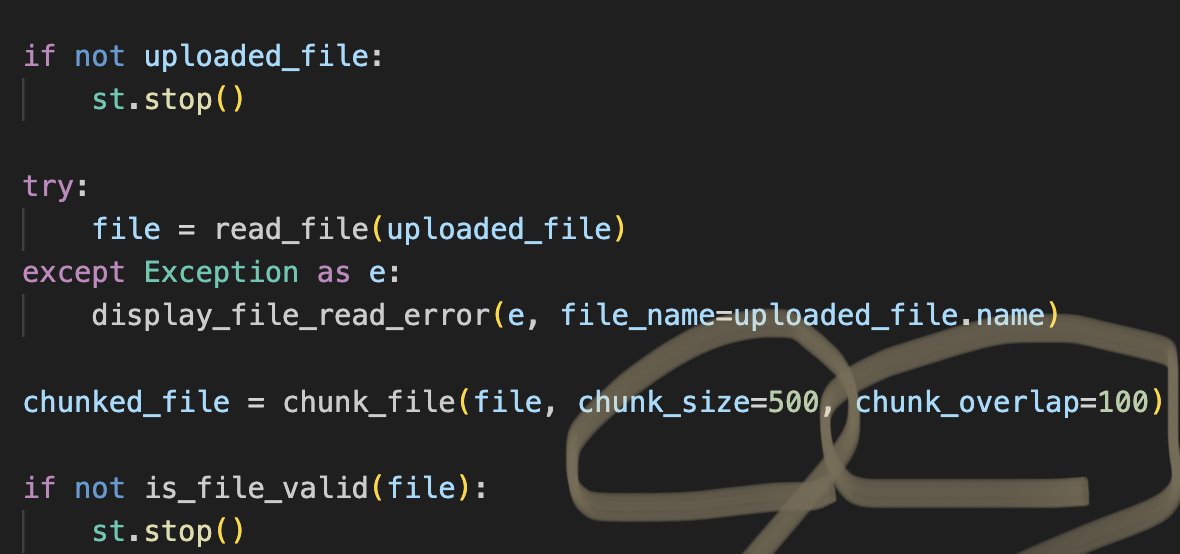
❑세부 설정 변경
- 작동 원리 : 사용자가 문서를 업로드하면, 이 문서는 여러 작은 부분으로 나눠져서 ‘벡터 인덱스’라는 독특한 형태의 데이터베이스에 저장되는데요, 이 벡터 인덱스는 의미적 검색과 검색이 가능하게 해 줍니다.
그리고 사용자가 질문을 제출하면, 이제 KnowledgeGPT가 벡터 인덱스를 활용해 문서 조각들 중에서 가장 관련성이 높은 부분들을 찾아냅니다. 그다음 단계에서는 GPT3가 등장해서, 최종적인 답변을 생성해 줍니다.

main.py
무엇이 정답이라고 하기는 어렵고 상황에 맞춰서 변경을 하면 좋을 것 같습니다.
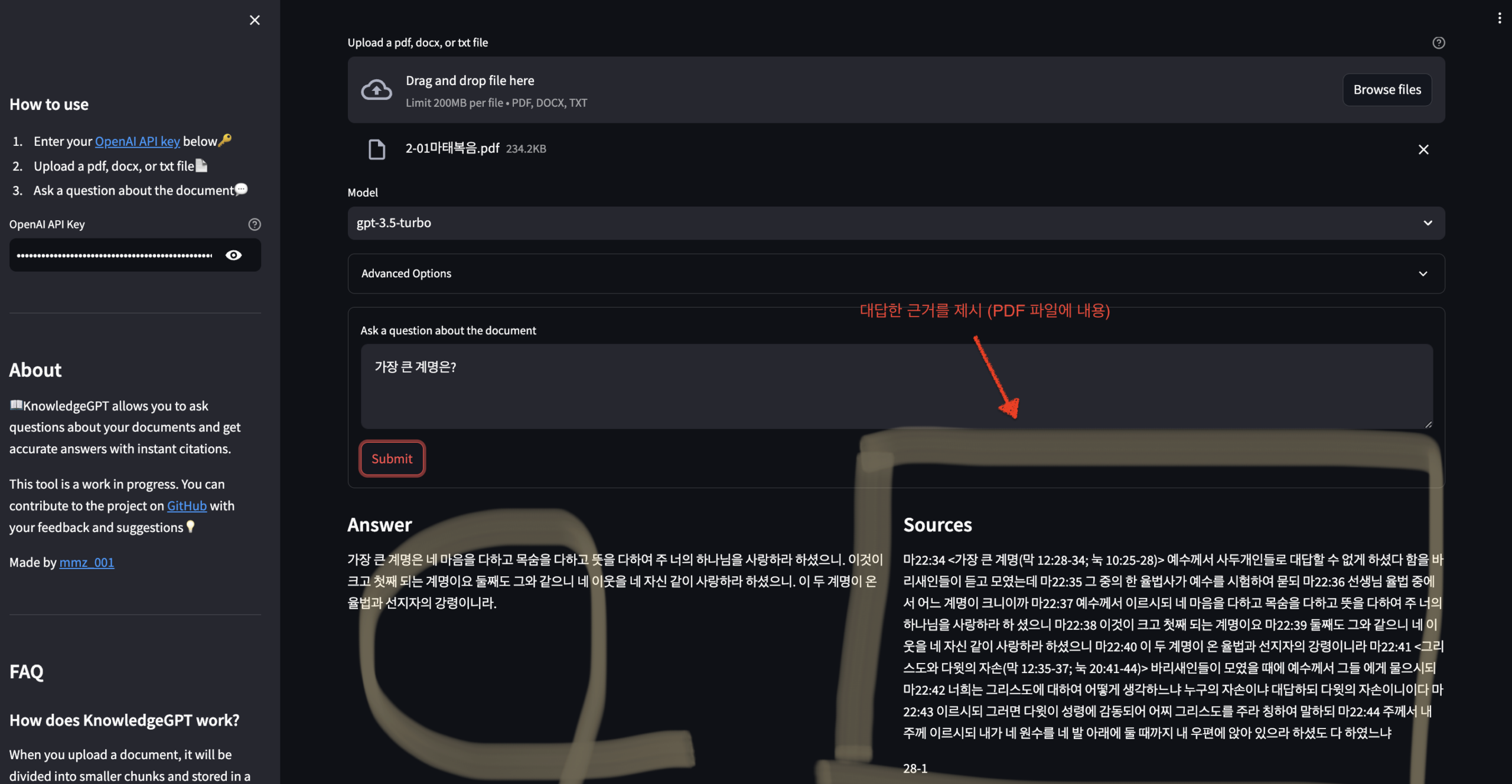
❑결과 및 결론
: 답변을 확인하면 PDF 내용을 바탕으로 대답을 잘했다는 것을 알 수 있습니다. 그러나, PDF 내용이 빈약하거나 전문적인 문서의 경우 정확한 답변을 하지 못했습니다. 아쉽게도, 한글의 정확도는 영문에 비해 많이 떨어졌습니다. 아직은 100% 대체하기는 어렵지만 실생활에 잘 활용하면 좋은 도구가 될 것 같네요.
참고 링크
GitHub – mmz-001/knowledge_gpt: Accurate answers and instant citations for your documents.