🐼 판다스(Pandas)란?
판다스는 파이썬에서 데이터 분석을 위한 라이브러리입니다. 주로 표 형태의 데이터를 처리하며, 데이터 가공, 정제, 분석 등을 효율적으로 수행할 수 있습니다. 판다스를 사용하면 대량의 데이터를 손쉽고 빠르게 처리할 수 있으며, 다양한 데이터 분석 기능을 제공합니다.
다음은 제가 생각하는 판다스의 주요 장점입니다:
빅데이터 처리: 판다스를 사용하면, 엑셀이나 구글 시트에서 열 수 없는 매우 큰 데이터(예: 연간 데이터 분석 등)를 처리할 수 있습니다.반복 작업 자동화: 실무에서는 RAW 데이터를 자주 다루며, 같은 작업을 반복하는 것은 비효율적입니다. 판다스를 사용하면 이런 반복 작업을 한 번에 자동화할 수 있습니다 (예: 날짜(Date)를 주(Week)나 월(Month)로 변환, 카테고리 자동 분류 등).데이터 구조 변경(Melt, Groupby 등): 판다스를 사용하면, Wide Form 데이터를 Long Form 데이터프레임으로 변환하는 등 데이터 구조를 자유롭게 변경할 수 있습니다.데이터 병합(Merge) 및 결합(Concat): 100개가 넘는 엑셀 파일 (월별로 정리된 데이터)을 합치는 것은 번거로울 수 있습니다. 그러나 판다스를 사용하면 코드 한 줄로 모든 데이터를 합치고 원하는 필터를 적용하여 분류할 수 있습니다.
이 외에도 판다스는 다양한 장점을 가지고 있어, 사무 및 분석 업무를 수행하는 많은 사람들에게 필수적인 도구입니다.
Google Colab 예제를 복사하여 아래의 예제를 직접 해보세요.
⌨️데이터 불러오기 (pd.read_csv)
: 판다스는 CSV, 엑셀 뿐만 아니라 다양한 파일 형식을 읽어 데이터 프레임(Data Frame)을 생성할 수 있습니다.
import pandas as pd #Pandas라는 Library 를 불러와서 pd 라고 이름 지음.
df = pd.read_csv("/content/sampledata/Call_Center.csv")
# 특정 경로에 있는 데이터를 가져올 경우 : r'경로파일이름.확장자'
# 같은 폴더에 있다면 : titanic = pd.read_csv("data/titanic.csv") 📌Options
✨encoding (참조 사이트)
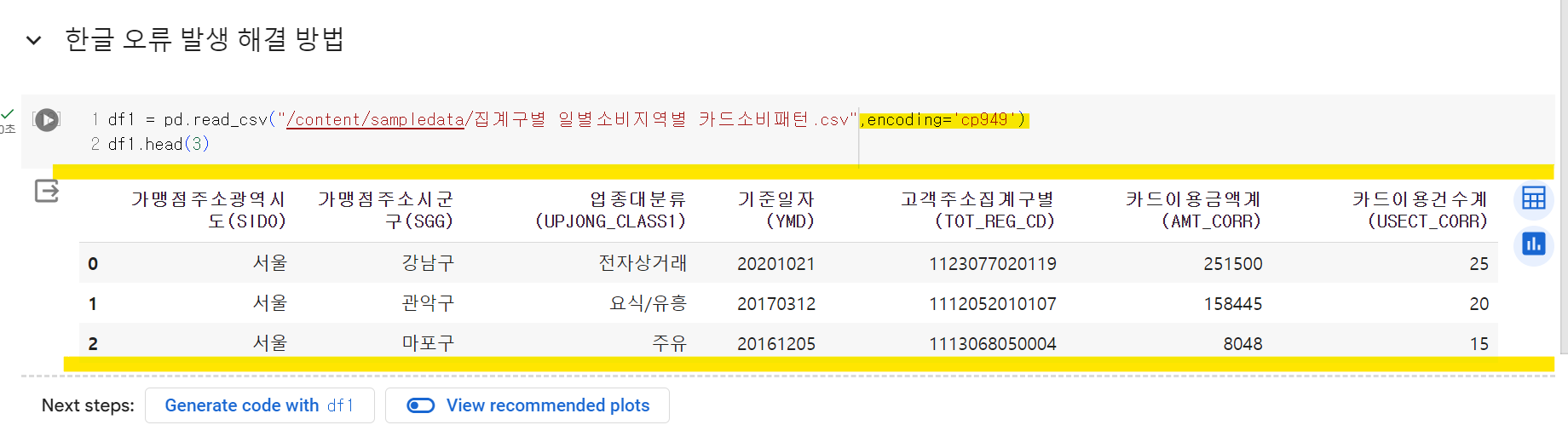
df = pd.read_csv(r'D:data.csv', encoding='cp949')
# 한글 폰트 깨지는 경우 : encoding='cp949' 또는 encoding='utf-8-sig'한글 오류 발생 (unicodedecodeerror ‘utf-8’ codec can’t decode byte)
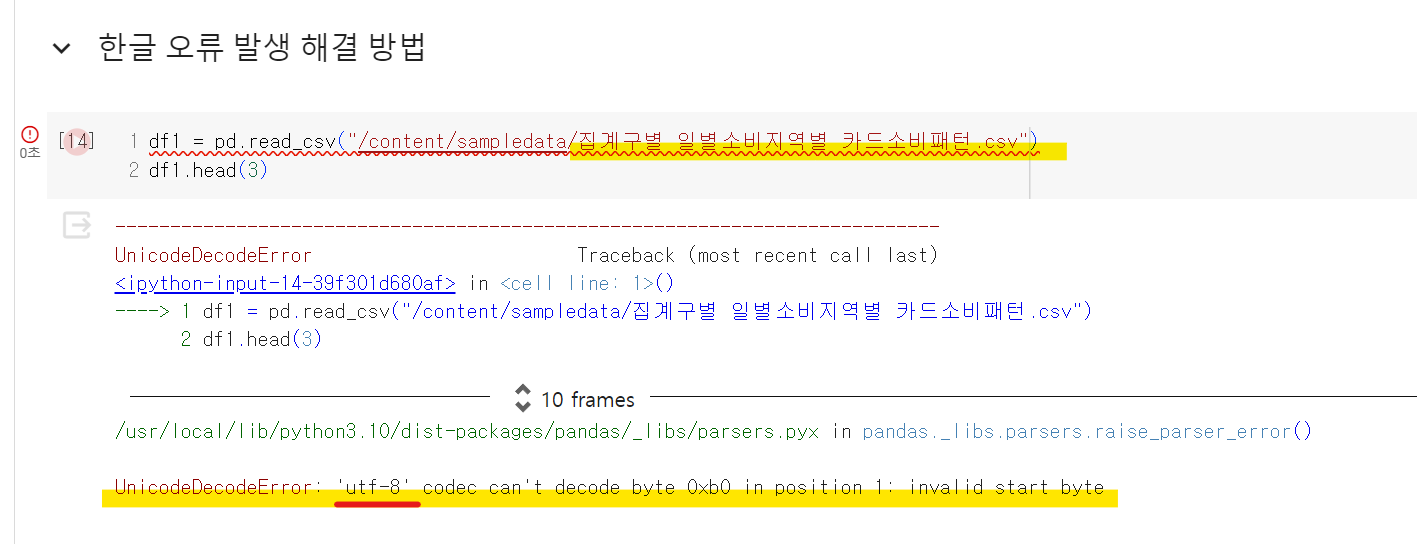
한글 오류 해결
✨skiprows
df = pd.read_excel(r'D:data.xlsx',skiprows=1)
# skiprows 1 : row를 건너뛰어 불러옴. ✨low_memory : (참조 사이트)
df = pd.read_csv(r'D:data.csv',low_memory=False)- Error Message : DtypeWarning: Columns have mixed types. Specify dtype option on import or set low_memory=False.
데이터 타입에 NaN 등이 있으면 발생, low_memory=False 로 문제 해결 가능
✨sep
df = pd.read_csv(r'D:data.csv',sep=',')
# 파일 분류 - CSV(Comma-separated values) 일반적으로 ',' 이지만, 때로는 ';' 로 구분된 경우가 있다. 이런 경우 sep=으로 문제 해결 가능✨header : 크게 사용할 일은 없음.
Default behavior is to infer the column names: if no names are passed the behavior is identical to header=0 and column names are inferred from the first line of the file.
기본값(Default)이 첫 번째 행을 헤더(Header)로 인식하므로, 크게 사용할 일은 없습니다.
df = pd.read_csv(r'D:data.csv',header=0)🦾데이터 전처리 (drop_duplicates, drop, fillna, rename etc)
📌Options
✨drop_duplicates() : (공식문서_참고) 중복 값 제거
✨drop() & dropna(): Pandas 라이브러리에서 데이터프레임의 특정 행 또는 열을 삭제하기 위해 사용되는 함수입니다. drop() 함수는 특정 열 또는 행을 삭제하는데 사용됩니다. 인자로는 삭제하려는 열 또는 행의 이름을 입력하고, axis 인자를 통해 열을 삭제할지 행을 삭제할지를 결정합니다. axis=0은 행을, axis=1은 열을 나타냅니다. 예를 들어, df.drop(columns=['B', 'C'])는 ‘B’와 ‘C’ 열을 삭제합니다. (공식홈페이지_참고)
✨dropna() 함수는 누락된 데이터를 가진 행 또는 열을 삭제하는데 사용됩니다. axis 인자를 사용해 행 또는 열을 선택하고, how 인자를 통해 ‘any’ 또는 ‘all’을 선택하여 하나라도 NaN값이 있는 행 또는 열을 삭제할지 모든 값이 NaN인 행 또는 열을 삭제할지 결정할 수 있습니다. inplace=True를 설정하면 원본 데이터프레임에 변경사항이 바로 적용됩니다. (공식홈페이지_참고)
✨fillna() : NaN 값을 다른 것으로 대체하는 것. (공식문서_참고)
✨rename() : 데이터프레임의 행 또는 열 이름을 변경하기 위해 사용됩니다. columns 인자를 사용하여 열 이름을 변경할 수 있으며, 기존 이름과 새 이름을 딕셔너리 형태로 전달합니다.inplace=True를 설정하면 원본 데이터프레임에 변경사항이 바로 적용됩니다.
ℹ️기본사항 확인 (예제)
df.shape # RAW 개수 & Column 개수
df.info() # 데이터 타입 확인
df.describe() # 연속형 데이터(숫자)만 뽑아서 Five number Summary를 보여줌
df.head() # 상위 N 개 데이터 출력
df.tail() # 하위 N 개 데이터 출력
df.columns # Column 이름 확인
df.columns.to_list() # Column 전체를 시트화
df['시도'].unique() # 범주형 데이터 항목을 보여줌
df['시도'].value_counts() #범주형 데이터 항목 갯수기본 내용까지 따라오신다고 고생하셨습니다. 기본 내용이 많아서 나누어 포스팅할 예정이니 예제 파일과 함께 포기하지 말고 학습하시길 바란다.
2탄으로
🗃️데이터 필터 (Conditional filtering)
판다스(Pandas)에서도 엑셀이나 구글 스프레드시트의 필터(Filter) 기능과 유사한 데이터 필터링이 가능합니다. Pandas에서는 ‘같다’를 나타낼 때 ‘=’ 대신 ‘==’를 사용하며, ‘같지 않다’는 ‘!=’ 또는 ‘~’로 표현합니다.
# 같다 : 예) 시군구 == '관악구'인 경우
df[df['시군구']=='관악구']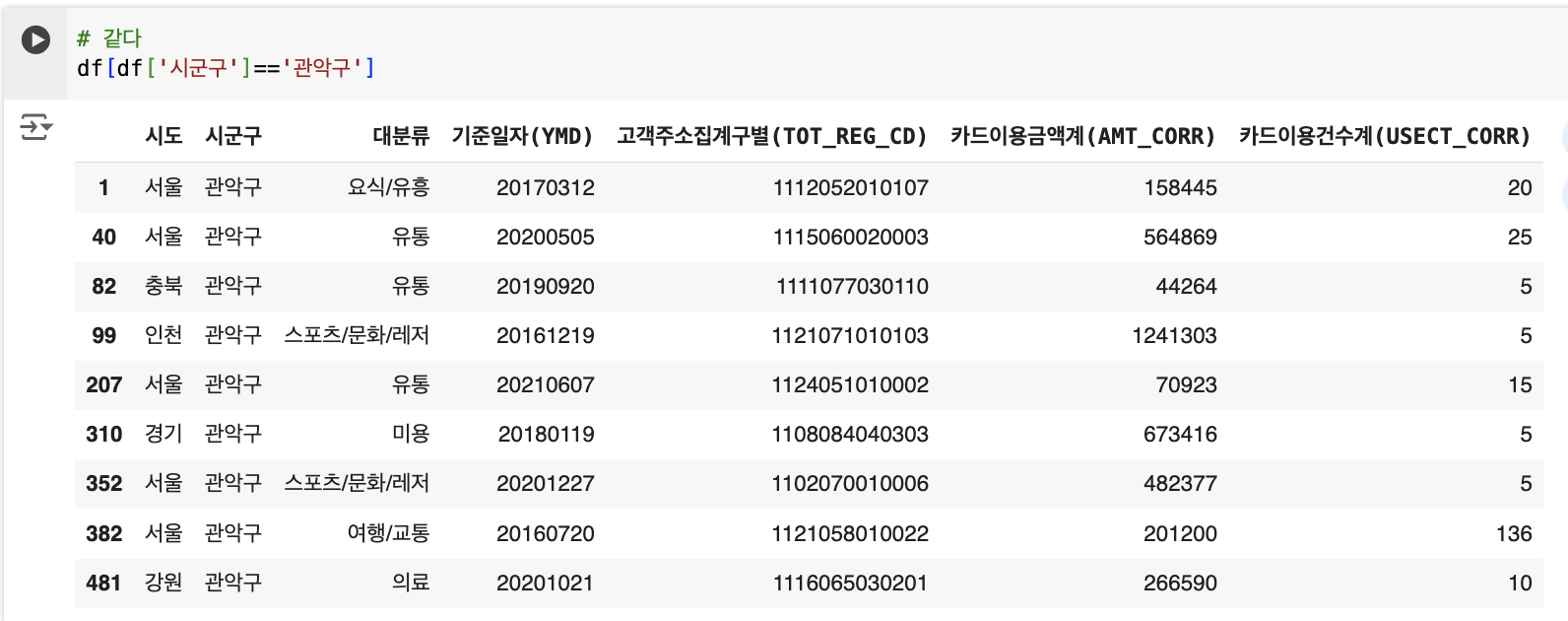
관악구를 제외 후 ‘시군구’의 unique() 값을 확인하면 정상적으로 빠져있는 것을 알 수 있다.
# 같지 않다 : 예) 시군구가 '관악구'가 아닌 경우
df[df['시군구']!='관악구']
df[~(df['시군구']=='관악구')]
-----------------------------------
Except = df[~(df['시군구']=='관악구')]
Except['시군구'].unique()
다중 조건 사용하기 AND = & , OR = |
# 관악구에서 카드이용금액계가 50,000이상인 경우 (2가지 조건 AND)
df[(df['시군구']=='관악구')&(df['카드이용금액계(AMT_CORR)']>=50000)].sort_values(by='카드이용금액계(AMT_CORR)',ascending=False)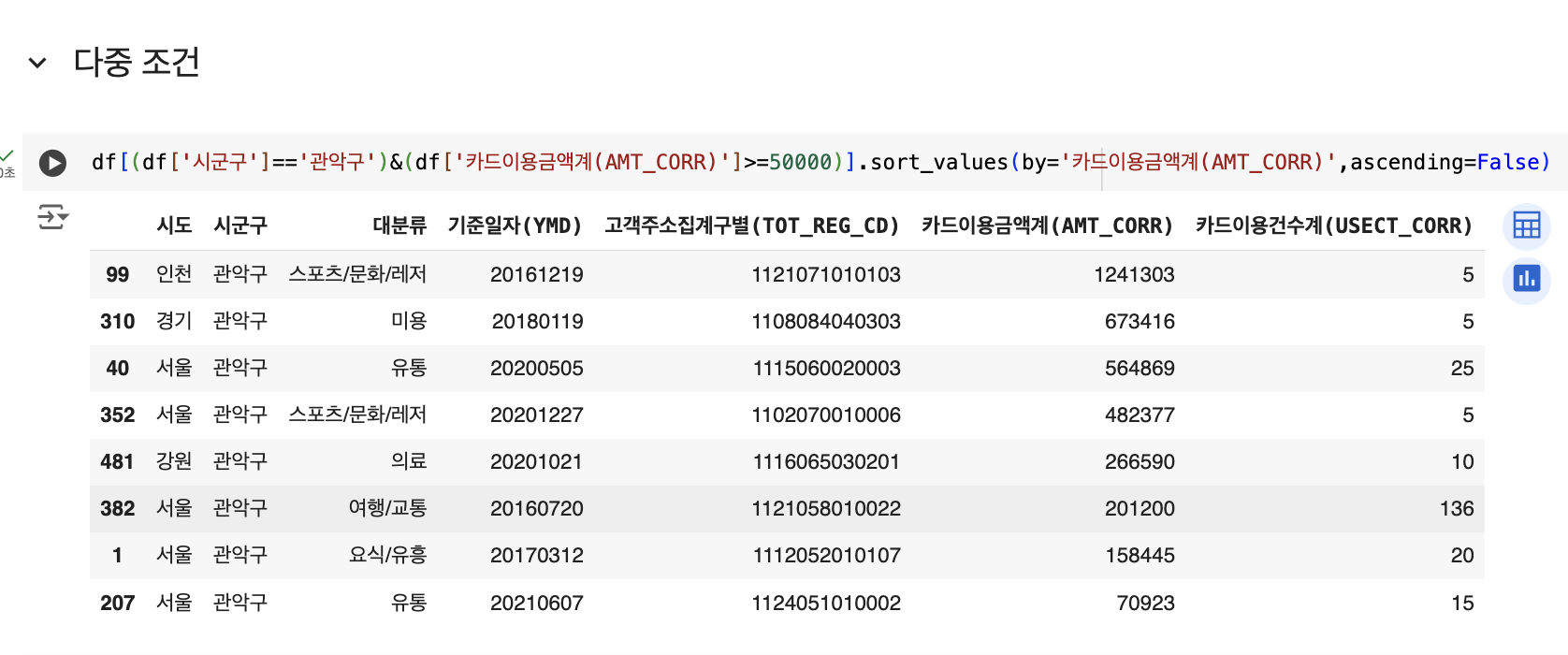
# '시도'가 제주 이거나, 카드이용금액이 500,000인 경우
df[(df['시도']=='제주') | (df['카드이용금액계(AMT_CORR)']>=5000000)].sort_values(by='카드이용금액계(AMT_CORR)',ascending=False)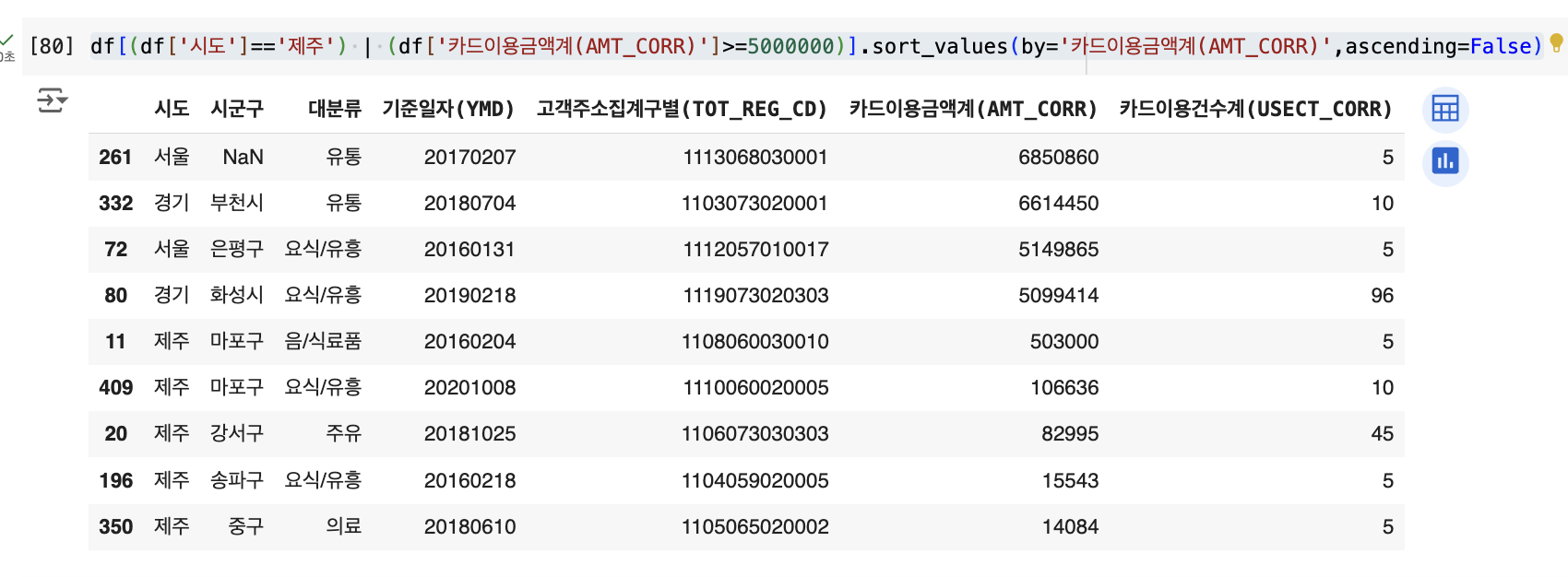
⏬ 데이터 정렬 (sort_values)
데이터 분석을 할 때 특정 열의 값을 기준으로 데이터를 정렬하는 것은 매우 중요합니다. Pandas에서는 sort_values() 메서드를 사용하여 데이터를 오름차순 또는 내림차순으로 정렬할 수 있습니다. 예를 들어, 카드 이용 금액을 기준으로 데이터를 내림차순으로 정렬하려면 아래와 같이 코드를 작성할 수 있습니다:
# 카드 이용 금액 내림차순 정렬
sorted_df = df.sort_values(by='카드이용금액계(AMT_CORR)', ascending=False)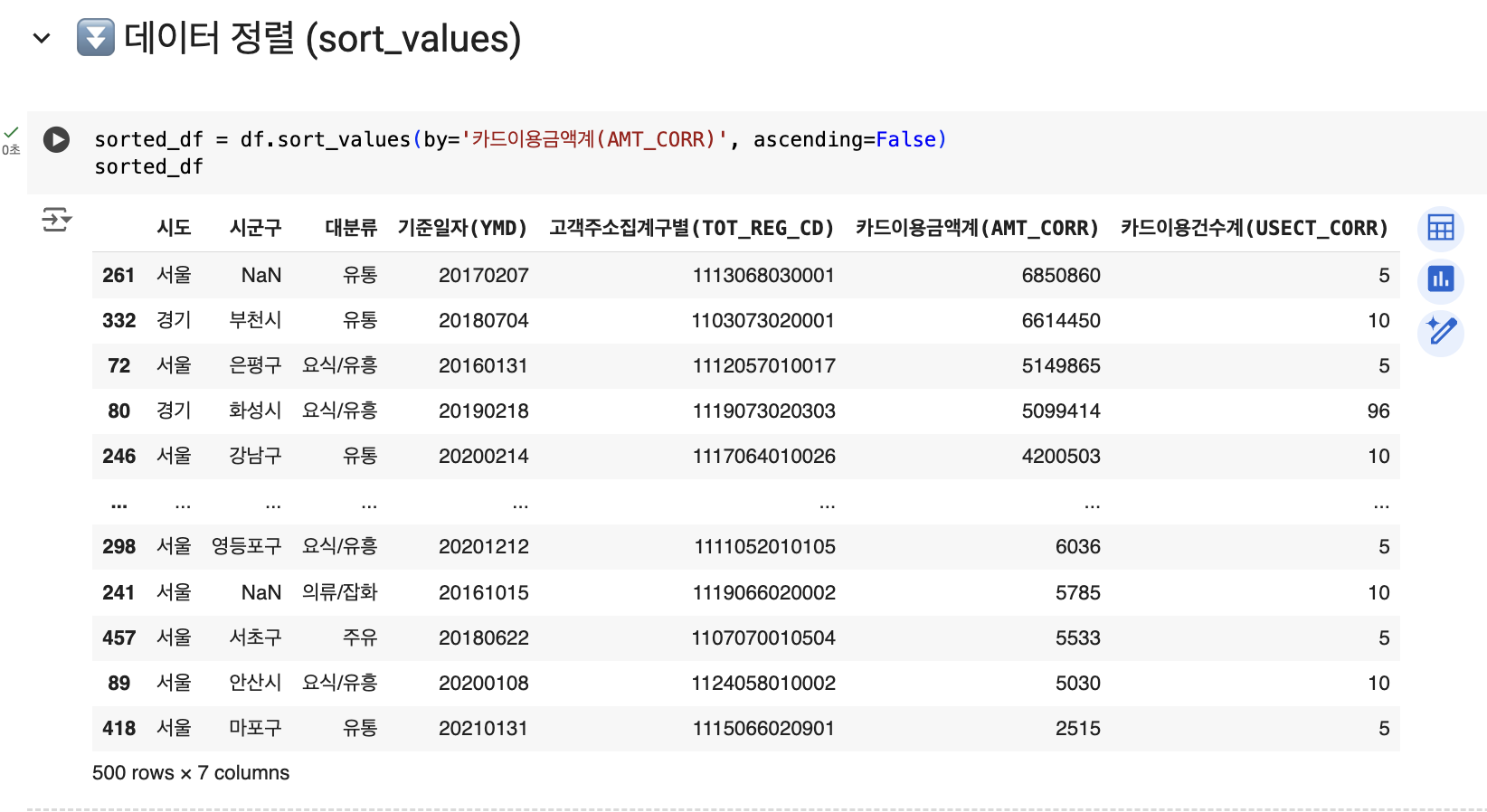
만약 여러 열을 기준으로 정렬하고 싶다면, 열 이름과 정렬 방식을 리스트로 지정합니다. 예를 들어, 대분류를 오름차순으로, 카드이용금액을 내림차순으로 정렬하려면 다음과 같이 작성합니다:
# 대분류 기준 오름차순, 카드 이용 금액 기준 내림차순 정렬
sorted_df1 = df.sort_values(by=['대분류', '카드이용금액계(AMT_CORR)'], ascending=[True, False])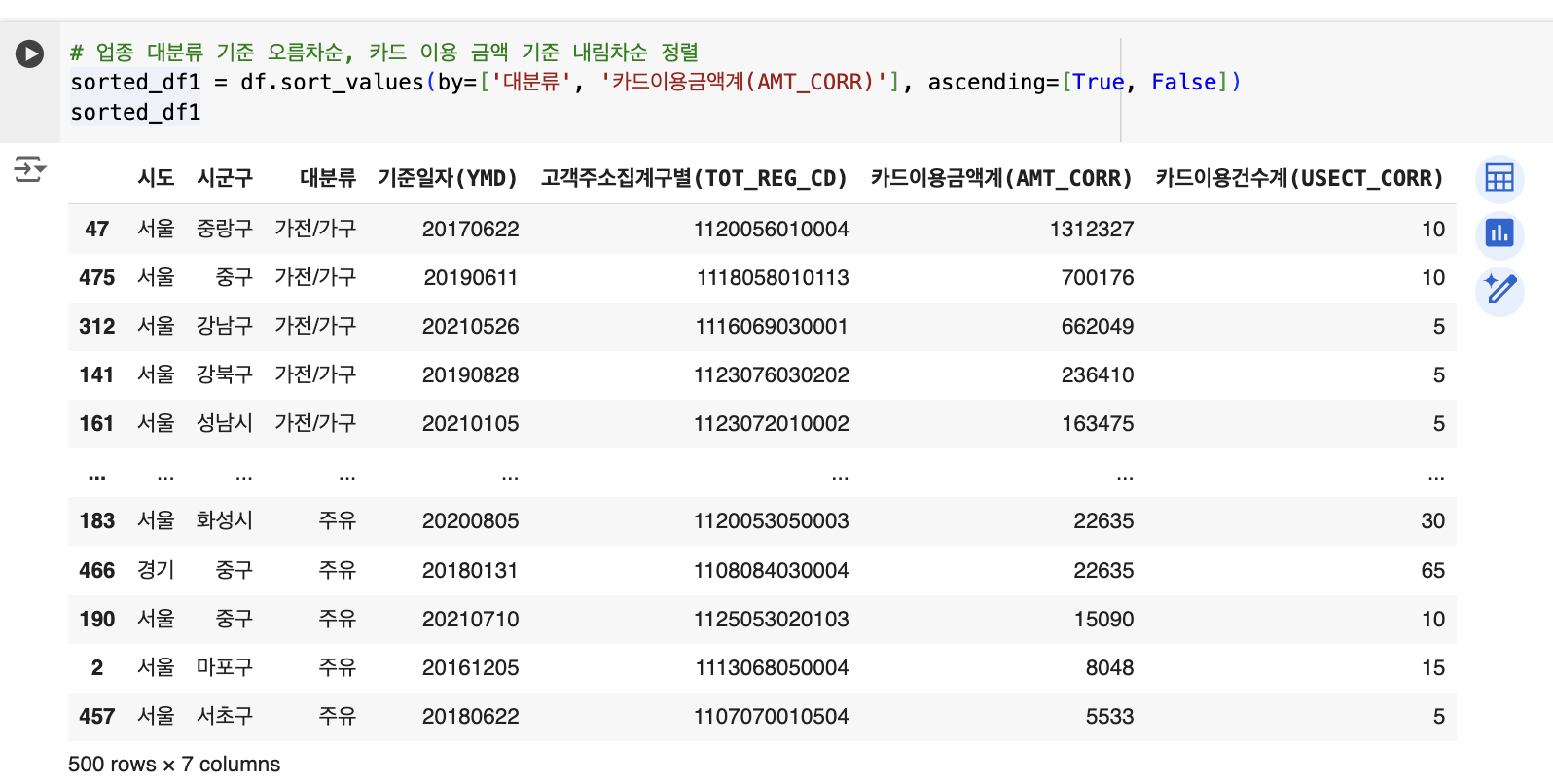
더 자세한 내용은 Pandas 공식 문서의 sort_values에서 확인할 수 있습니다.
🔗 병합 (Merge)
데이터 분석 시 여러 데이터 소스를 하나로 합치는 작업이 필요할 때가 많습니다. Pandas에서는 merge() 함수를 사용하여 두 개 이상의 데이터프레임을 특정 키 값을 기준으로 병합할 수 있습니다. 예를 들어, 고객 정보와 거래 내역이 각각 다른 데이터프레임에 저장되어 있을 때, 고객ID를 기준으로 두 데이터를 병합할 수 있습니다

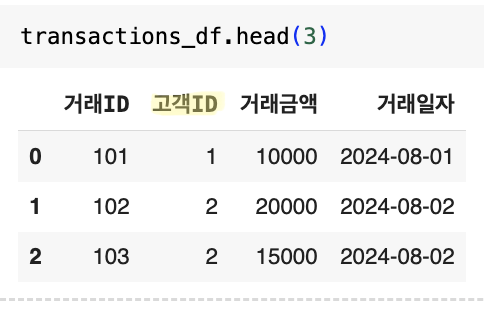
# '고객ID'를 기준으로 왼쪽 조인
merged_df = pd.merge(customers_df, transactions_df, how='left', on='고객ID')만약 병합하려는 데이터프레임의 키 값이 서로 다를 경우, left_on과 right_on 파라미터를 사용하여 각 데이터프레임의 키 값을 지정할 수 있습니다
# 고객 데이터의 '고객ID'와 거래 데이터의 '고객_아이디' 기준 병합
merged_df1 = pd.merge(customers_df1, transactions_df1, how='left', left_on='고객ID', right_on='고객_아이디')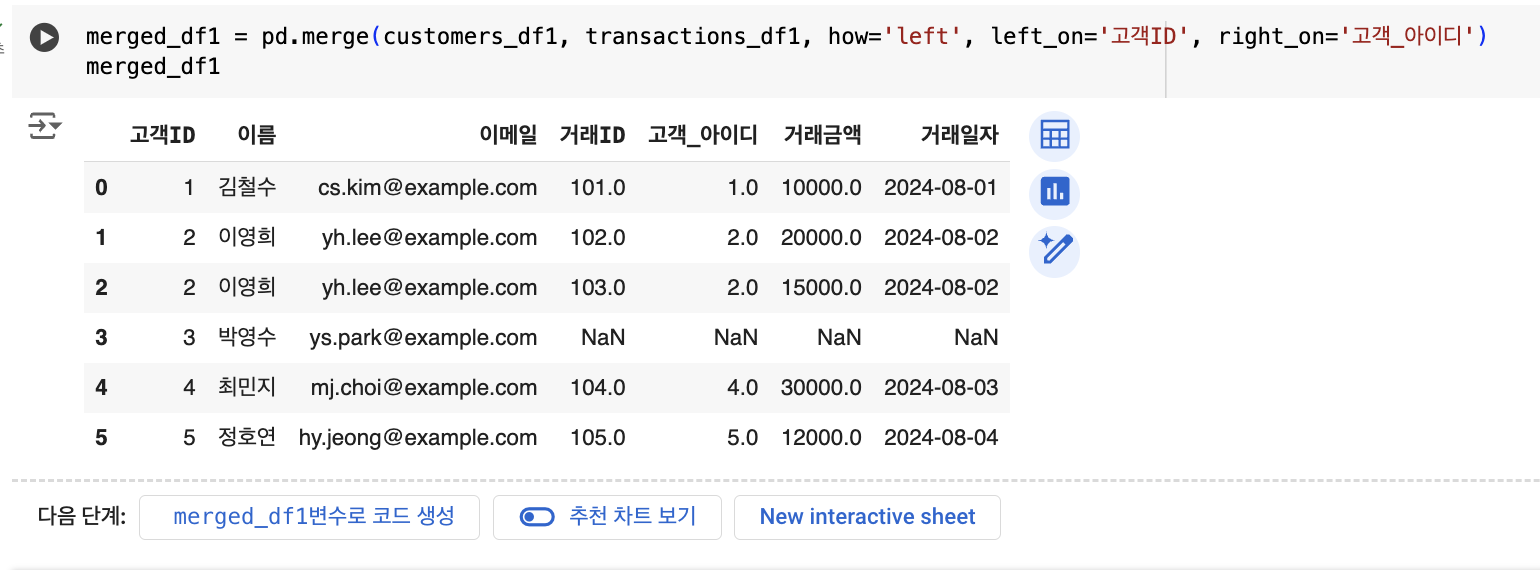
병합에 대한 더 많은 옵션과 자세한 설명은 Pandas 공식 문서의 merge에서 확인할 수 있습니다.
🗃️ Concatenate (concat)
여러 개의 데이터프레임을 하나로 합쳐야 하는 경우가 종종 있습니다. 이때 concat() 함수를 사용하여 데이터를 세로로 또는 가로로 결합할 수 있습니다. 예를 들어, 두 개의 데이터프레임을 세로로 결합하여 모든 데이터를 한 데이터프레임에 통합하려면 다음과 같이 할 수 있습니다:
# 데이터프레임 세로 결합
concatenated_df = pd.concat([df1, df2], axis=0)
concatenated_df
# 데이터프레임 가로 결합
concatenated_df1 = pd.concat([df1, df2], axis=1)
concatenated_df1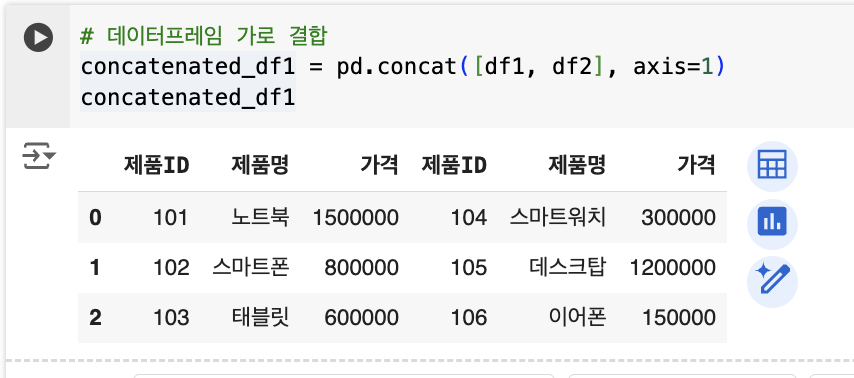
이 방법은 데이터의 크기가 크거나, 동일한 구조의 여러 파일을 하나로 합쳐야 할 때 매우 유용합니다. 가로로 결합할 경우, axis=1로 설정하면 됩니다.
자세한 사용법은 Pandas 공식 문서의 concat에서 확인할 수 있습니다.
👥 Group by ⭐❗
Pandas의 groupby()는 데이터를 특정 열을 기준으로 그룹화한 후 집계 함수를 적용하여 요약된 결과를 얻을 수 있는 강력한 기능입니다. 예를 들어, 업종별로 카드 이용 금액의 평균, 중앙값, 표준편차를 계산하고자 할 때 다음과 같이 작성할 수 있습니다:
# 업종별 카드 이용 금액의 평균, 중앙값, 표준편차 계산
groupby_df = df.groupby('업종대분류(UPJONG_CLASS1)')['카드이용금액계(AMT_CORR)'].agg(['mean', 'median', 'std'])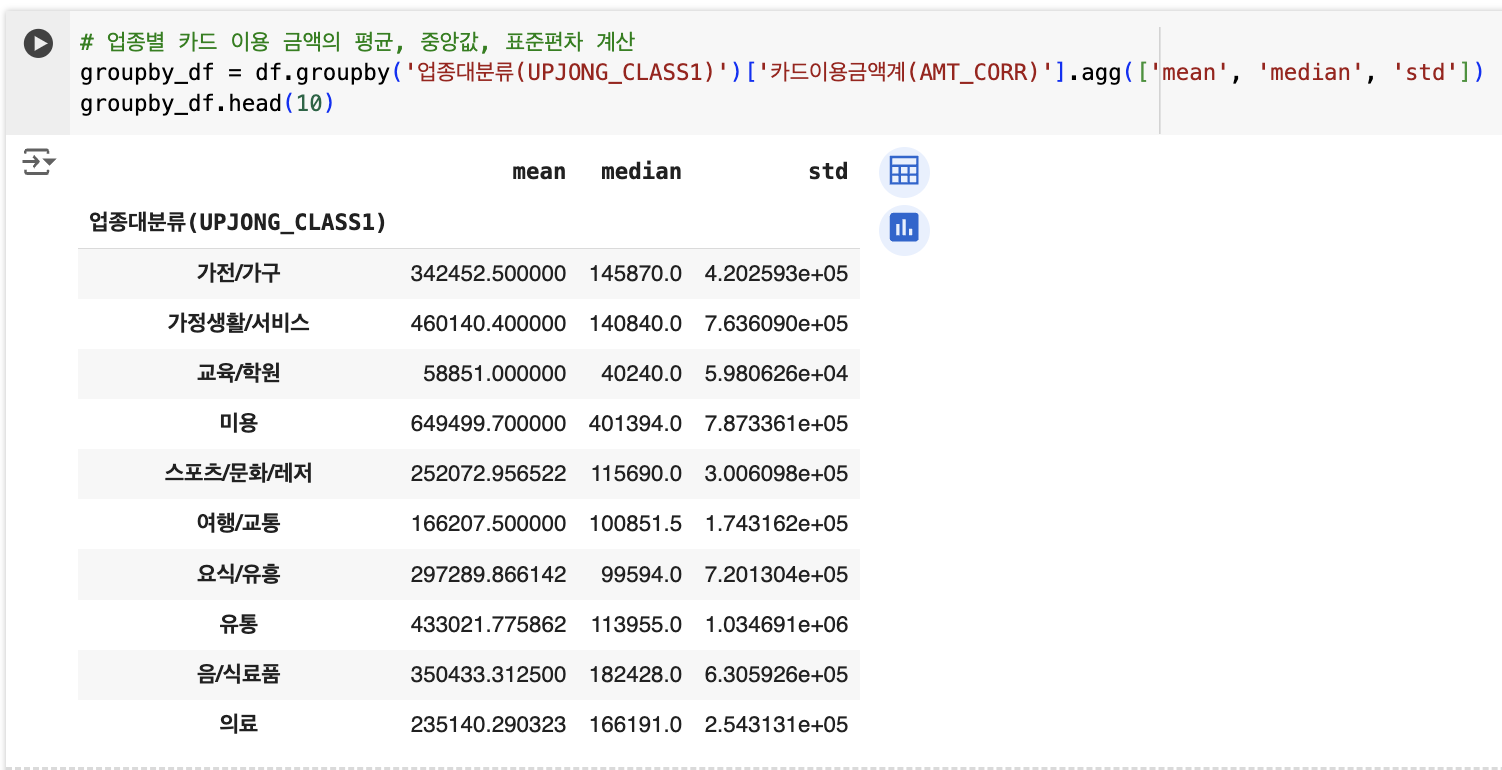
이 코드에서는 업종 대분류를 기준으로 그룹화하여 카드 이용 금액에 대해 평균(mean), 중앙값(median), 표준편차(std)를 계산합니다. 그룹화된 데이터를 다양한 방식으로 요약할 수 있어 데이터 분석에 매우 유용합니다.
더 자세한 설명은 Pandas 공식 문서의 groupby에서 확인할 수 있습니다.
𝄜 피벗테이블 (pd.pivot_table)
피벗 테이블은 데이터를 요약하여 다양한 관점에서 분석할 수 있게 해줍니다. Pandas의 pivot_table() 함수를 사용하면 특정 기준으로 데이터를 집계할 수 있습니다. 예를 들어, 월별로 카드 이용 금액의 합계를 계산하고자 할 때는 다음과 같이 작성할 수 있습니다:
# 월별 카드 이용 금액 합계 피벗 테이블
pivot_df = pd.pivot_table(data=df, index='기준일자(YMD)', values='카드이용금액계(AMT_CORR)', aggfunc='sum')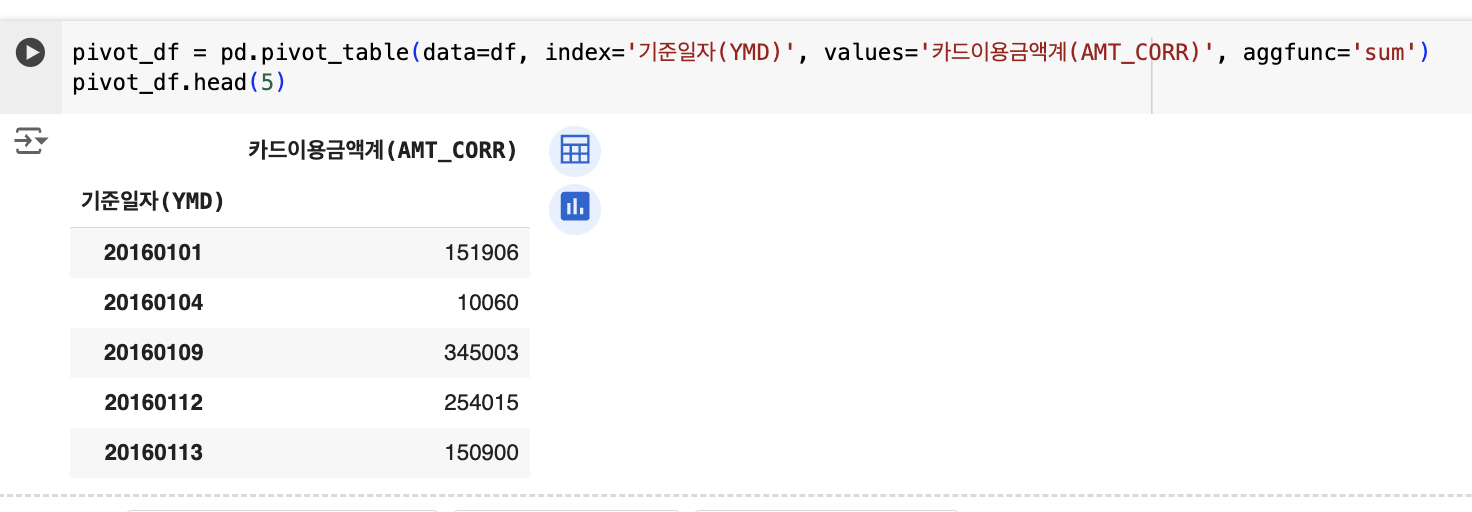
이 코드에서는 기준일자(YMD)를 기준으로 카드이용금액계(AMT_CORR)의 합계를 계산하여 피벗 테이블을 생성합니다. 다양한 집계 함수를 적용할 수 있으며, 데이터를 보다 체계적으로 분석할 수 있습니다.
피벗 테이블에 대한 자세한 내용은 Pandas 공식 문서의 pivot_table에서 확인할 수 있습니다.
Archived
# 연령대가 40대인 것만 필터 !!
df[df['연령대']=='40대'] # 이렇게 해도 구할 수는 있지만, 정답은 아래에
cond1 = (df['연령대']=='40대') #조건 설정
df.loc[cond1] # YouTube에서는 이렇게 알려주네.
# 연령대가 40대 빼고 필터 !!
cond1 = (df['연령대']!='40대') # 조건을 변경하거나
df.loc[~cond1] # 컨디션 앞에 ~ (물결표시)로 정리 가능
--------------------------------------------------------------------------
# 30대 여성, 구매금액 높은 순
# 연령대 = '30대이하' & 성별 ='여'
cond1 = df['연령대'] == '30대이하'
cond2 = df['성별'] =='여'
df3 = df.loc[cond1 & cond2].sort_values(by='구매금액', ascending=False)
# cond 말고 바로 쓰려면 () 가 중요하다
# AND = & , OR = |
df[(df['Marital_Status'] == "Married") | (df['Marital_Status'] == "Single")]
--------------------------------------------------------------------------
# Athlete Column에 Florence문자를 포함하는 값만 필터
oo[oo.Athlete.str.contains('Florence')]
movies = movies[movies['genres'].str.contains('Fiction')]Error :ValueError: Cannot mask with non-boolean array containing NA / NaN values
: This error occurs when you attempt to find the rows in a DataFrame that contain a specific string, but the column you’re searching in has NaN values. You can fix this error by replacing NaN values with False values using Series.fillna(False) or by specifying na=False in Series.str.contains(pattern, na=False)12. (from Bing)
NaN 값이 있어서 발생하는 문제이기에 movies= movies.fillna("blank") 이후에 아래 코드 실행하면 됨.
⏬데이터 정렬 (sort_values)
df.sort_values(by='Column Name', ascending=False)
# 구매금액 내림차순 ascending 부분을 안쓰면 오른차순
df.sort_values(by=['구매수량','연령'],ascending=[False,True]).iloc[:10]
#여러 조건을 정렬 할 때 [] List 사용. 오름차순, 내림차순도 마차가지!
#구매수량은 내림차순(많은것 부터), 연령은 오름차순(어린 사람부터) 정렬
#마지막으로 iloc[:10] 를 통해서 상위 10개
**단순하게 정렬이 아니라, 정렬이 기존 데이터에 반영 하게 하려면
df = df.sort_values(by='Column Name', ascending=False) 형식으로 만들어야 한다. 🔗병합 (Merge)
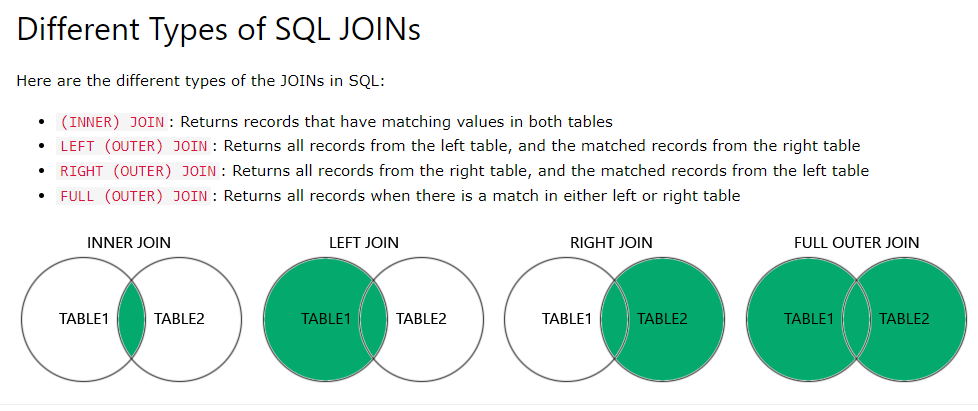
#Key Value 같은 경우
result = pd.merge(df1, df2, how='left', on='id')
#Match Key Value 다른 경우
rsults2 = pd.merge(df1,df2, how='left', left_on='Ticket ID', right_on='Ticket_ID')
#Key Value 가 2개 이상인 경우 (예 _ 이름 + 날짜 합친게 Key _ Roster 데이터)
rsults3 = pd.merge(df1, df2, on=["Name","Date"], how="left")📌PRO TIP
파일 합치기 (OS 활용) : 한 폴더에 있는 파일 하나로 합치기
# Step 1: Import packages and set the working directoryimport os
import glob
import pandasas pd
import pandasqlas ps
import datetimeas dt
import math
import time
os.chdir(r"C:RAW") #경로 정하기
# Step 2: Use glob to match the pattern ‘csv’extension= 'csv'
all_filenames= [ifor iin glob.glob('*.{}'.format(extension))]
#combine all files in the listcc= pd.concat([pd.read_csv(f, sep=',', low_memory=False, header=0)for fin all_filenames ])🗃️ Concate()
>>> s1 = pd.Series(['a', 'b'])
>>> s2 = pd.Series(['c', 'd'])
>>> pd.concat([s1, s2])
0 a
1 b
0 c
1 d
dtype: object👥 Group by ⭐❗
: Missing Value 가 있는 경우 Groupby는 기본적으로 Missing Value Row는 제외해버린다. Fillin을 통해서 Missing Value를 다른 값으로 채우거나, dropna=False를 통해서 해당 문제를 해결할 수 있다. 상황에 맞게 처리하자 !
aggregated = df.groupby('category')['price'].agg(['mean', 'median', 'std'])𝄜 피벗테이블 (pd.pivot_table)
# pivot_table(데이터 소스, 열(row), 값, 계산(Sum, mean etc)
pd.pivot_table(data=df1, index='월',values='출고수량',aggfunc='sum')iloc vs loc
-------------------------------------------------------------------------
df.iloc[:,8:-2]
# index location 약자 [0:10] 0번 부터 10까지 row 를 불러온다. 여기에 , (comma)를 넣으면 몇 번째 Columns을 불러올지 !! 오
# iloc[index , Column]💡 **# 판다스 분석을 위한 기본 세팅 (한글 폰트 포함)**
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib as mpl
mpl.rc('font',family='Malgun Gothic')