https://tts.life-debugging.com
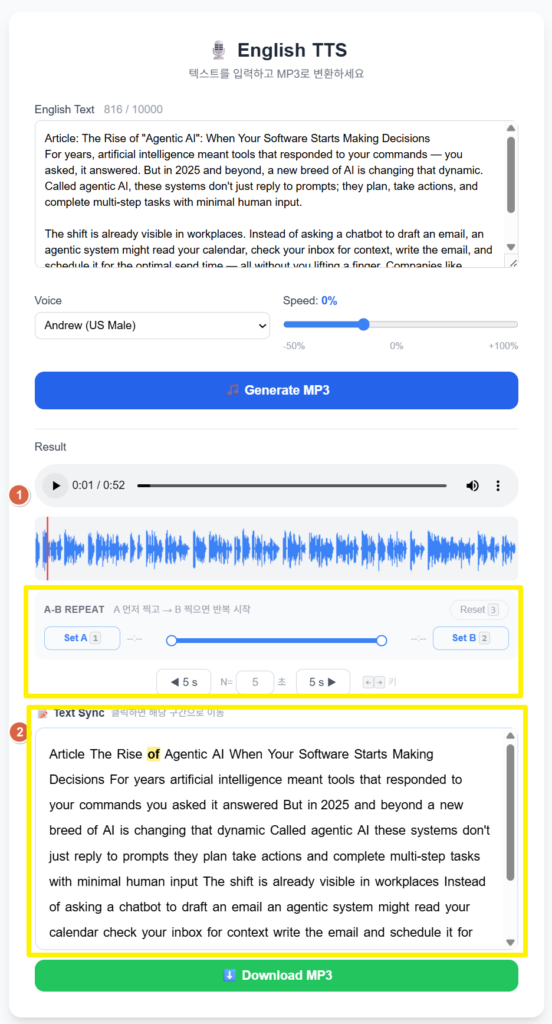
지난번에 라즈베리파이 홈서버에 edge-tts 기반 TTS 웹앱을 만들었는데, 쓰다 보니 아쉬운 점이 생겼습니다. 음원을 생성하고 나면 그냥 오디오 플레이어만 덩그러니 있고, 특정 구간으로 빠르게 이동하거나 반복 청취하는 게 불편했습니다. 영어 공부용으로 활용하려면 단어별 하이라이트와 클릭-시크 기능이 있으면 완전히 달라질 것 같았습니다. 그래서 한 번에 몰아서 고도화했습니다.
✅ 추가된 기능
- 오디오 파형(Waveform) 시각화 — 생성 즉시 파란색 파형 + 빨간 플레이헤드 실시간 이동
- 파형 클릭으로 해당 위치 바로 이동(seek)
- N초 스킵 버튼 (◀ 5s / 5s ▶) — N값 자유 변경, 화살표 키로도 조작
- A-B 구간반복 키보드 단축키 — 1번: Set A, 2번: Set B, 3번: Reset
- Spacebar로 재생/일시정지 토글
- 📝 Text Sync 패널 — 재생 중 현재 단어 노란 하이라이트, 단어 클릭 시 해당 구간으로 이동
🛠 기술 스택
- 백엔드: Flask + edge-tts (Python)
- 파형 시각화: Web Audio API (
AudioContext.decodeAudioData+ Canvas) - 단어 싱크: edge-tts
WordBoundary이벤트 - 프론트엔드: Vanilla JS + Tailwind CSS
- 배포: Docker (라즈베리파이 5)
📡 핵심 — edge-tts WordBoundary 이벤트
이번 고도화의 핵심은 edge-tts의 communicate.stream() API입니다. 기존에는 communicate.save()로 MP3 파일만 저장했는데, stream()을 쓰면 오디오 청크와 함께 각 단어의 타이밍 정보(WordBoundary)도 함께 받을 수 있습니다.
단, 기본값이 SentenceBoundary라 반드시 boundary="WordBoundary"를 명시해야 합니다. 이걸 빠뜨리면 words 배열이 빈 채로 옵니다.
async def _generate_tts(text, voice, rate):
communicate = edge_tts.Communicate(
text=text,
voice=voice,
rate=f"{'+' if rate >= 0 else ''}{rate}%",
boundary="WordBoundary", # 반드시 명시!
)
audio_chunks, words = [], []
async for chunk in communicate.stream():
if chunk["type"] == "audio":
audio_chunks.append(chunk["data"])
elif chunk["type"] == "WordBoundary":
words.append({
"text": chunk["text"],
"offset_ms": int(chunk["offset"] / 10000), # 100ns → ms
"duration_ms": int(chunk["duration"] / 10000),
})
return {"audio_bytes": b"".join(audio_chunks), "words": words}offset과 duration은 100 나노초 단위이므로 10,000으로 나누면 밀리초가 됩니다. 또한 stream()은 예전 문서에 (type, data) 튜플로 소개된 경우가 있는데, 실제 최신 버전은 TTSChunk 딕셔너리 하나를 yield합니다. chunk["type"], chunk["data"]로 접근해야 합니다.
📤 API 응답 형식 변경 — blob → JSON
기존에는 MP3를 바이너리 blob으로 바로 내려줬는데, 단어 타이밍 데이터를 함께 전달하려면 JSON으로 바꿔야 했습니다. 오디오는 base64로 인코딩해서 같이 보냅니다.
# 백엔드
result = asyncio.run(_generate_tts(text, voice, rate))
audio_b64 = base64.b64encode(result["audio_bytes"]).decode("ascii")
return jsonify({"audio": audio_b64, "words": result["words"]})// 프론트엔드 — base64 디코딩 후 Blob URL 생성
const json = await res.json();
const binaryStr = atob(json.audio);
const bytes = new Uint8Array(binaryStr.length);
for (let i = 0; i < binaryStr.length; i++) bytes[i] = binaryStr.charCodeAt(i);
const blob = new Blob([bytes], { type: "audio/mpeg" });
audio.src = URL.createObjectURL(blob);🎨 파형 시각화 — Web Audio API
파형은 외부 라이브러리 없이 Web Audio API만으로 구현했습니다. MP3 ArrayBuffer를 decodeAudioData()로 PCM 데이터로 변환한 뒤, 캔버스에 픽셀 단위로 min/max 샘플을 그립니다. 한번 그린 파형은 getImageData()로 스냅샷을 저장해두고, requestAnimationFrame 루프에서 매 프레임마다 복원 후 빨간 플레이헤드만 덧그립니다.
function drawStaticWaveform(audioBuffer) {
const data = audioBuffer.getChannelData(0);
const step = Math.ceil(data.length / W);
ctx.strokeStyle = "#3b82f6";
ctx.beginPath();
for (let x = 0; x < W; x++) {
let min = 1, max = -1;
for (let s = 0; s < step; s++) {
const sample = data[x * step + s] || 0;
if (sample < min) min = sample;
if (sample > max) max = sample;
}
ctx.moveTo(x, mid + min * mid);
ctx.lineTo(x, mid + max * mid);
}
ctx.stroke();
canvas._staticImageData = ctx.getImageData(0, 0, W, H); // 스냅샷 저장
}📌 주의: decodeAudioData()는 ArrayBuffer를 detach(전송)할 수 있습니다. Blob URL을 만든 bytes.buffer를 그대로 넘기면 이후 사용이 불가능해지므로, bytes.buffer.slice(0)으로 복사본을 전달해야 합니다.
📝 단어 싱크 패널
백엔드에서 받은 단어 배열을 각각 <span> 태그로 렌더링합니다. audio.timeupdate 이벤트에서 현재 재생 시간에 해당하는 단어를 찾아 노란색(#fef08a)으로 하이라이트합니다.
단어 수가 많을 수 있으므로 binary search로 O(log n) 탐색하고, 이전 하이라이트 인덱스와 비교해 변경이 없으면 DOM 조작을 건너뜁니다. 단어를 클릭하면 audio.currentTime을 해당 offset으로 이동시키고 바로 재생합니다.
// Binary search로 현재 단어 탐색
audio.addEventListener("timeupdate", () => {
const ms = audio.currentTime * 1000;
let lo = 0, hi = wordData.length - 1, found = -1;
while (lo <= hi) {
const mid = (lo + hi) >> 1;
if (wordData[mid].offset_ms <= ms) { found = mid; lo = mid + 1; }
else hi = mid - 1;
}
if (found === lastHighlightedIdx) return; // 변화 없으면 skip
lastHighlightedIdx = found;
// DOM 업데이트 + scrollIntoView
});⌨️ 키보드 단축키 정리
- Space — 재생 / 일시정지
- ← → — N초 뒤로 / 앞으로 (기본 5초, 변경 가능)
- 1 — A 구간 설정
- 2 — B 구간 설정 (설정 즉시 A→B 반복 시작)
- 3 — A-B 리셋
textarea나 input에 포커스 중일 때는 단축키가 동작하지 않도록 document.activeElement.tagName을 체크합니다.
🚀 배포
수정은 두 파일(app.py, static/index.html)만으로 완결됩니다. Dockerfile이 COPY로 파일을 이미지 내부에 넣는 방식이라, 수정 후에는 반드시 재빌드가 필요합니다. 컨테이너 재시작만으로는 변경사항이 반영되지 않습니다.
docker build -t tts-web . &&
docker stop tts-web && docker rm tts-web &&
docker run -d --name tts-web -p 8095:5000 --restart unless-stopped tts-web마치며
가장 삽질한 부분은 두 가지였습니다. 첫째는 boundary="WordBoundary" 파라미터를 빠뜨려서 단어 데이터가 빈 배열로 와서 한참을 헤맨 것, 둘째는 communicate.stream()이 튜플을 yield한다고 잘못 알고 있었던 것입니다. 실제로는 TTSChunk 딕셔너리를 yield합니다. edge-tts 문서가 버전마다 달라서 직접 소스를 열어보는 게 가장 확실합니다. 영어 공부할 때 단어 클릭으로 해당 구간을 바로 들을 수 있으니, 앞으로 훨씬 유용하게 쓸 것 같습니다. 🙂